
Mit dem neuen W3C Standard RDF 1.2 lassen sich Knowledge Graphen sehr gut um Zeit, Provenienz- und auch Konfidenzaussagen zu einem (temporalen) Context Graph erweitern. Der Beitrag beschreibt die Grundlagen, einige Anwendungsfälle und die Funktionen des Prototypes. Dieser stellt eine Visualisierung, Import- und Exportfunktionalitäten und Abfrage- und Validierungsmöglichkeiten mit einer SPARQL-1.2-Engine und einem SHACL-Validator zur Verfügung.
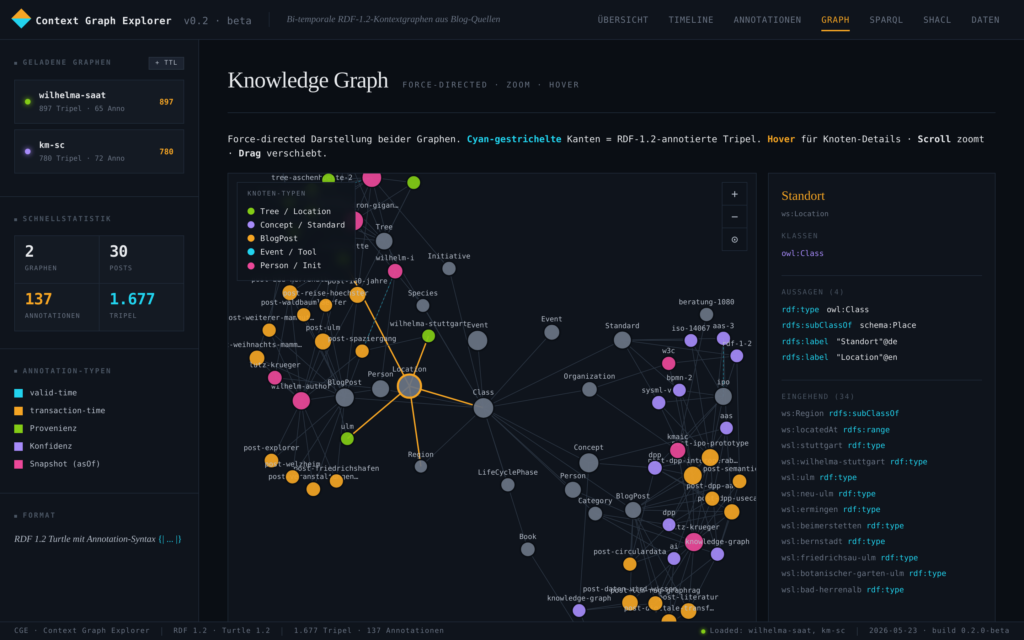
Ein klassischer Knowledge Graph beantwortet die Frage „was hängt womit zusammen?“, dargestellt als gerichteter Graph durch Knoten und Kanten. Ein Context Graph ergänzt diese Aussagen um weitere Dimensionen die im Kontext des Knotens stehen, z.B.:
- valid-time — wann war die Aussage in der realen Welt gültig?
- transaction-time — wann wurde sie erfasst, bestätigt oder revidiert?
- Provenienz und Konfidenz — woher stammt sie und wie verlässlich ist diese Aussage?
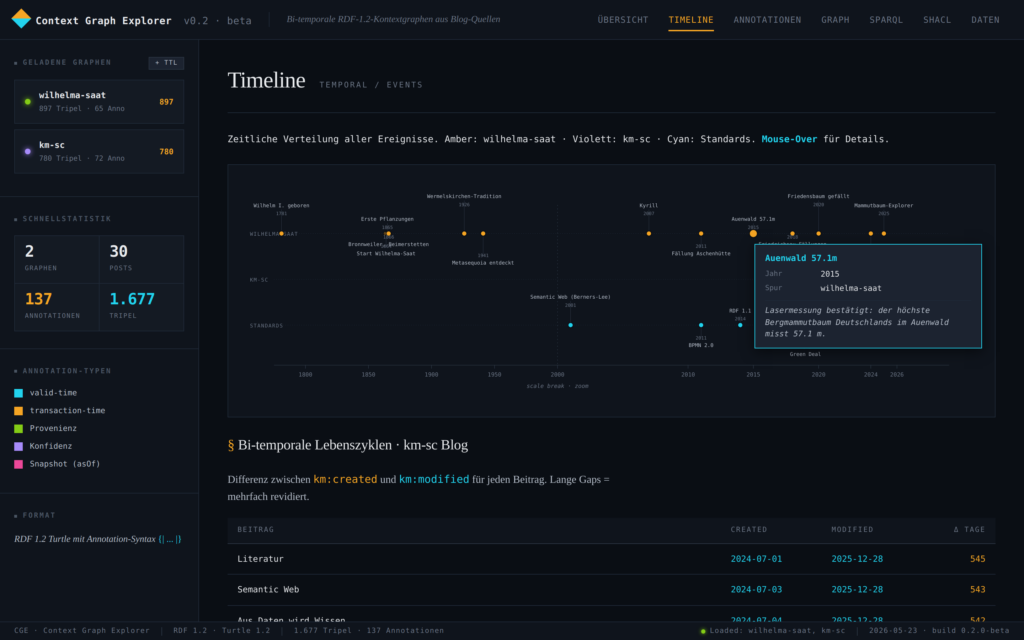
Mit dem W3C-Standard RDF 1.2 lässt sich dies sehr gut durch die Annotation Block-Syntax – mit geschweiften Klammern und Pipe-Strichen angeben – hier für einen Mammutbaum im Auenwald, der am 1.9.2015 mit einer Höhe von 57,1 m vermessen worden ist.
wst:tree-auenwald ws:heightMeters "57.1"^^xsd:decimal {|
ws:validFrom "2015-09-01"^^xsd:date ;
ws:source wsb:post-hoechster-mammutbaum-deutschlands ;
ws:certainty "bestaetigt" ;
ws:confidence "1.0"^^xsd:decimal ;
ws:recordedAt "2015-10-01T12:00:00Z"^^xsd:dateTime
|} .Diese Erweiterung des Knowledge Graphen ist z.B. im Zusammenhang mit dem Produktentwicklungsprozess, dem Digitalen Produktpass (DPP) oder bei der Verwaltung historischer oder regulierter Daten ein grosser Mehrwert – die Daten ändern sich zu bestimmten Zeitpunkten, Quellen wechseln, neue oder erweiterte Regulierungen treten in Kraft — mit dem Context Graph kann dies vollständig dokumentiert und später über Abfargen und auch Validierungen genutzt werden.
Für den Prototype wurden aus zwei unterschiedlichen Quellen jeweils ein Context-Graph generiert.
- Wilhelma-Saat — Veröffentlichungen zu einem Naturprojekt, welches die historischen Bergmammutbäume der „Wilhelma-Saat“ von König Wilhelm I. von Württemberg (aus dem Jahr 1864) dokumentiert. Der Context Graph enthält 897 Tripel mit 65 Annotationen, dokumentiert wird die Zeitspanne von 1781–2026. ( https://www.wilhelma-saat.de )
- KMAIC Blog — der Blog der KMAIC Website, jeder Beitrag mit Zeitstempeln für Erstveröffentlichung und Modifikation. Der Context Graph enthält 780 Tripel mit 72 Annotationen. ( https://www.km-sc.de )
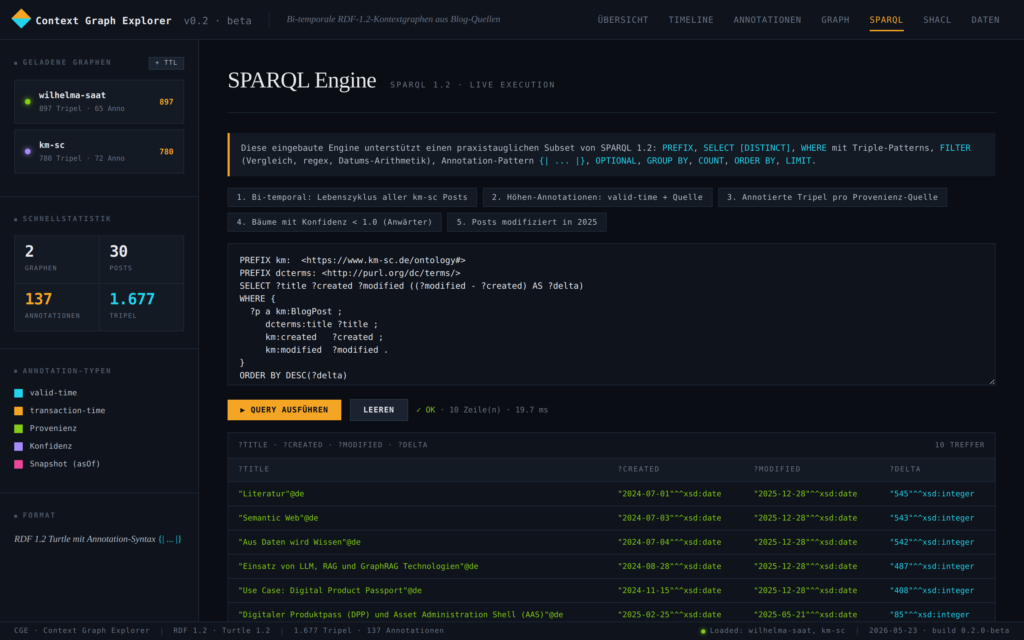
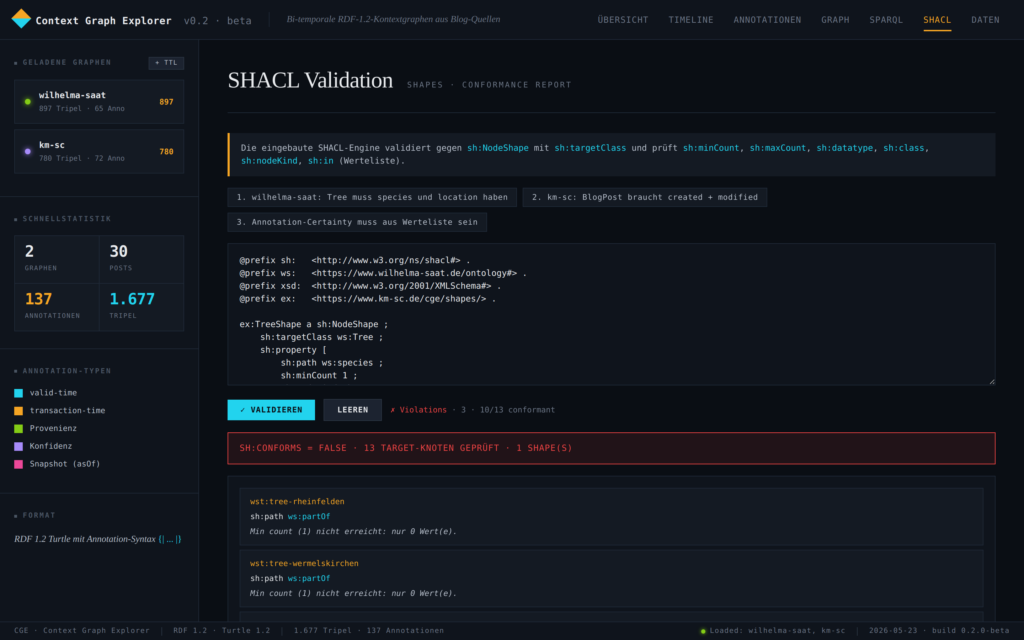
Der Prototype kann die Context Graphen im RDF-Format einlesen und diese als Graph oder Timeline visualisieren. Mit der eingebauten SPARQL-Engine sind die Details abfragbar, mit der eingebauten SHACL-Engine sind diese zusätzlich validierbar.
Ausblick
Ein Context Graph ist die logische Weiterentwicklung des Wissensgraphen. Sein Mehrwert entsteht dort, wo statische Aussagen ohne Zusatzdimension unzureichend sind. Weitere Anwendungen und Use Cases erscheinen auch in folgenden Bereichen sinnvoll:
- Regulatorik (DPP, ESPR, Batterie-Verordnung 2023/1542) verlangt nachvollziehbare Datenherkunft und -aktualität — beides ist direkt als Annotation modellierbar, mit SPARQL abfragbar und mit SHACL validierbar.
- Produkt-Management, Digital Twin, Product Carbon Footprint erfordern ein Tracking, wenn sich Produkt-Eigenschaften über die Zeit ändern (Wartungszustand, Recyclate-Anteil, CO₂-Footprint, etc.).
- Moderne AI-basierte Wissensmanagement-Systeme profitieren von Provenienz- und Konfidenz-Annotationen, wenn GraphRAG generierte Aussagen neben validierten Aussagen eines Domainexperten koexistieren – der Context Graph kann angeben, welche Quelle welche Aussage zu welchem Zeitpunkt liefert und wie vertrauenswürdig diese ist.