Wenn in einer Firma Menschen, AI-Agenten und Humanoide Roboter gleichermaßen in Business Prozessen und Wertschöpfungsketten involviert sind, ist man oft in einer hierarchischen Organisationsform nicht in der Lage, agil und unmittelbar auf Änderungen des Marktes zu reagieren. Hier kann es sehr nützlich sein, über andere Organisationsformen nachzudenken. Holacracy ist eine mögliche Alternative.
Holacracy ist eine selbstorganisierende Organisationsform für Unternehmen, welche 2007 von Brian J. Robertson formalisiert wurde. Statt einer, nur aus Personen bestehenden Hierarchie (in Form von Gruppen, Abteilungen, etc.) gibt es eine Struktur aus Rollen mit klar definierten Bestandteilen:
- Purpose – Ziele, Fähigkeiten und das Potential der Rolle,
- Domain – die Assets und Processe, über welche die Rolle autoritativ entscheidet,
- Accountabilities – fortlaufende Aufgaben, die die Rolle in der eigenen Domain verantwortet oder die Support-Aufgaben für andere Domains darstellen.
Einen Rahmen für die Tätigkeiten bilden Policies, die spezifisch für die Domain oder zentral für das gesamte Unternehmen anzuwenden sind.
Rollen sind in Kreisen (Circles) gruppiert und organisiert. Strukturänderungen werden nicht „angeordnet“, sondern gemeinsam in Governance-Meetings als Reaktion auf eine konkrete Tension (eine wahrgenommene Diskrepanz zwischen Ist und Soll) beschlossen.
Es findet eine Trennung zwischen Rolle <> Person statt. Eine Rolle wird von einer Person „energisiert“. Was passiert aber, wenn der „Energizer“ kein Mensch mehr ist, sondern eine intelligente, selbstlernende (AI-basierte) Maschine?
Ein AI-Agent (z.B. ein AI-basierter Agent für die Wartungs-Diagnose) hat einen Purpose für eine Domain (z. B. „Diagnose-Empfehlungen für den Betrieb der Maschine „HUMA-7“). Er hat selbständig fortlaufende Accountabilities auszuführen (Logs der Maschine überwachen, Anomalien melden, Reports erzeugen, Notifications zu versenden, eine Prediction auf der Basis realer Daten zu treffen). Strukturell unterscheidet ihn nichts von einem menschlichen Rollen-Inhaber.
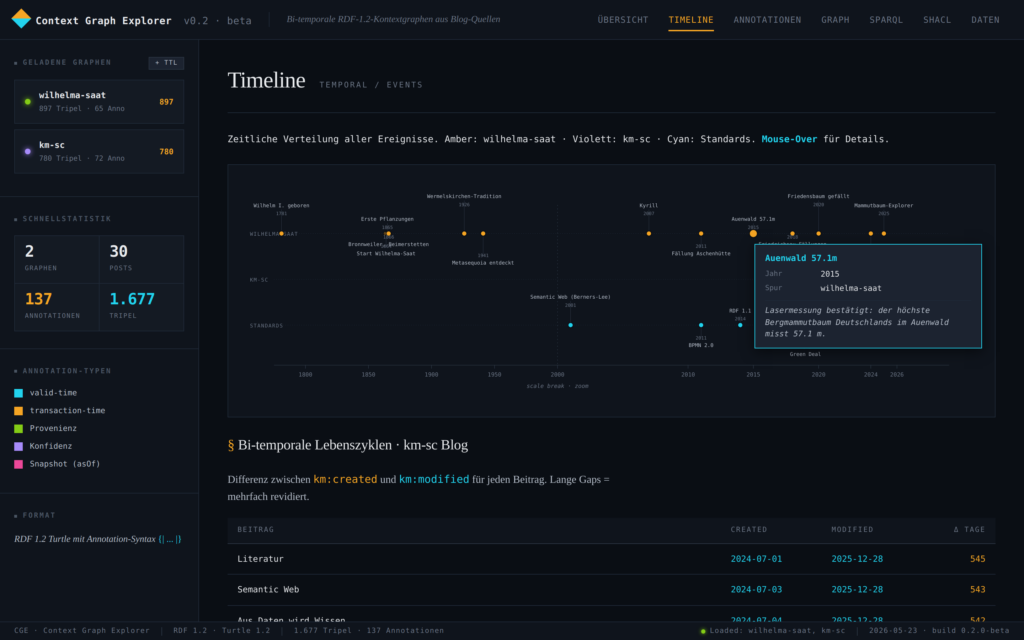
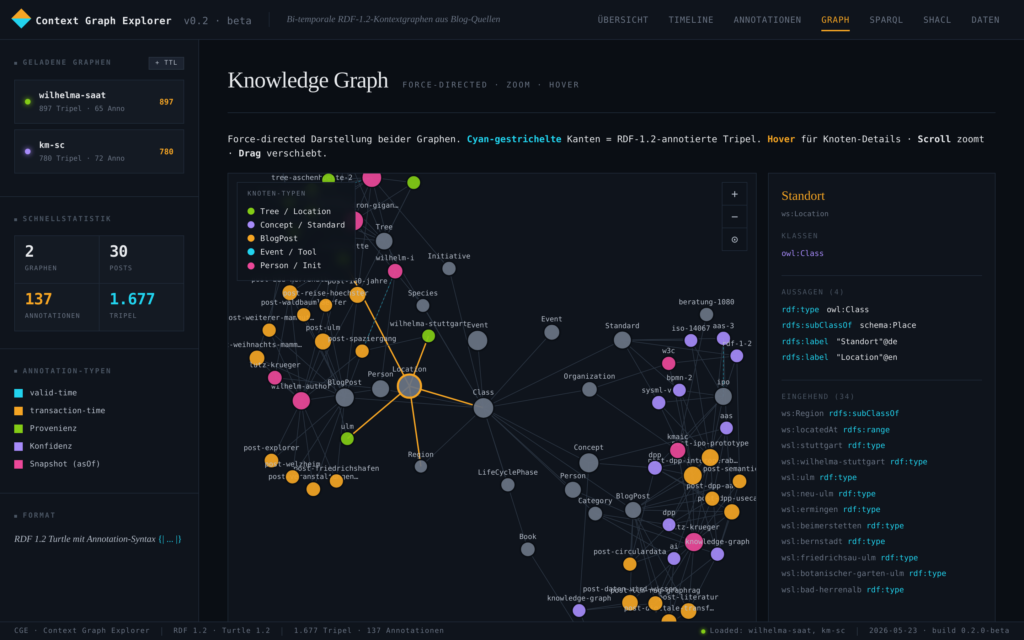
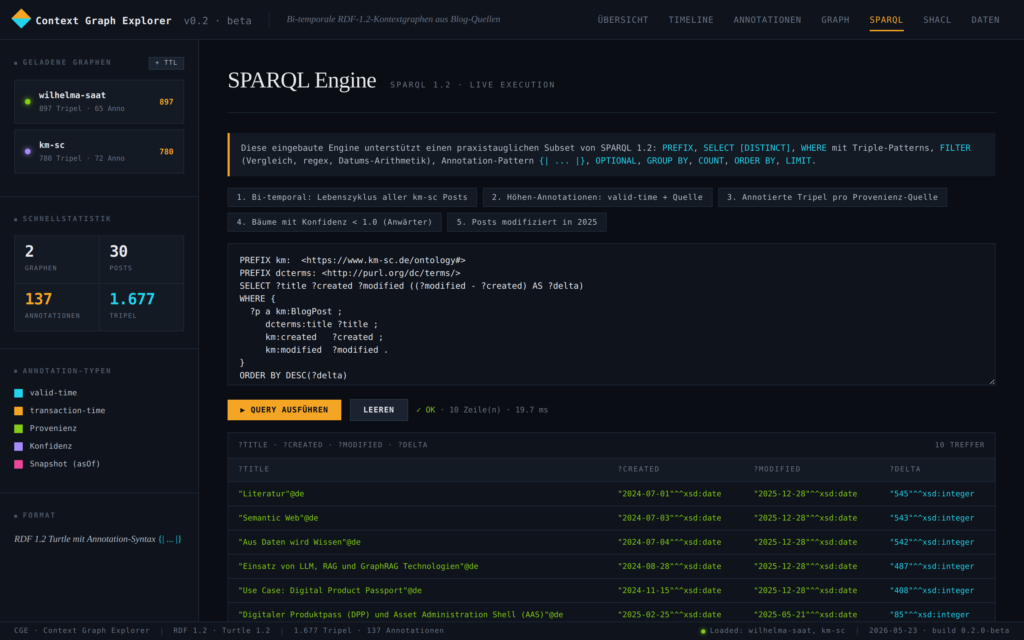
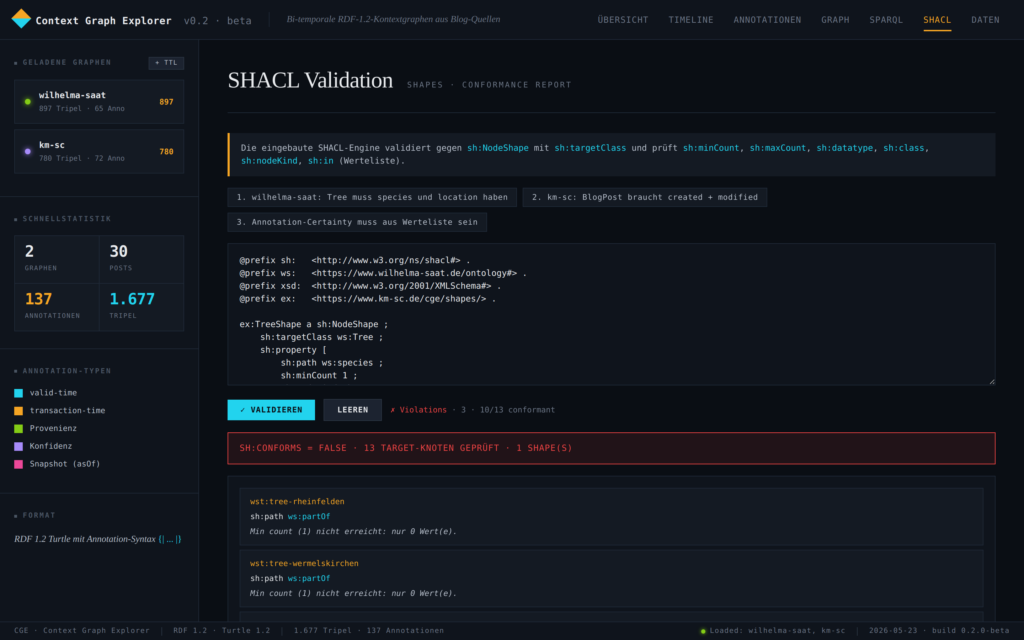
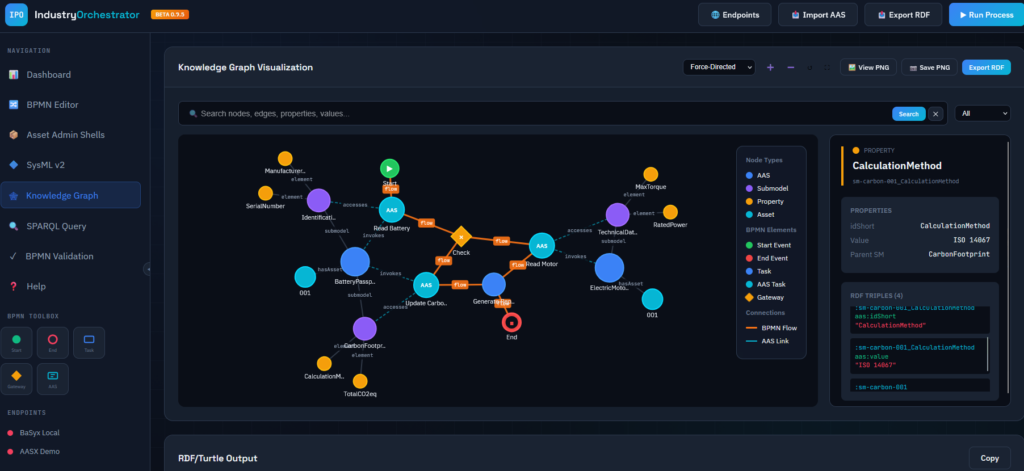
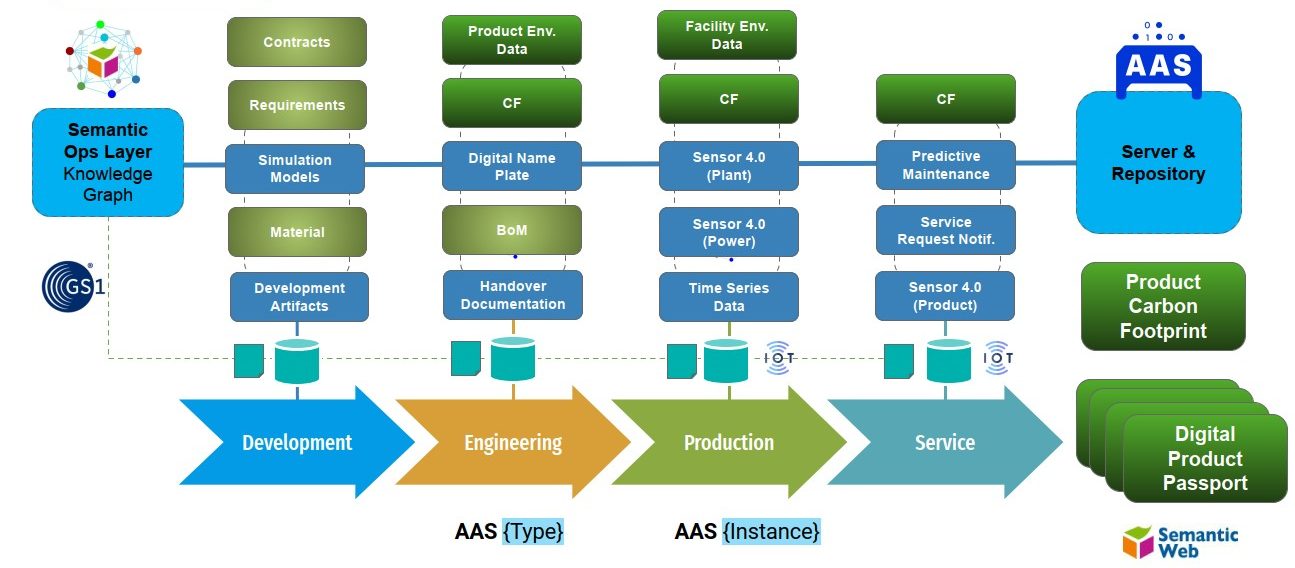
Zur Veranschaulichung wurde eine konkrete (fiktive), aber technisch plausible Anwendung – die Produktion eines humanoiden Roboters (HUMA-7) – in einem Prototype entwickelt. Im simulierten Unternehmen sind 13 Menschen angestellt sowie 6 AI-Agents und 8 Humanoide Roboter im Einsatz. Der Prototype kann mit verschiedene Visualisierungen, Simulationen und unterschiedlichen Optimierungsstrategien gesteuert und beobachtet werden. Ein Hauptmodul des Prototypes ist das semantische Modell des gesamten Unternehmens, welches auch die zeitlich abhängigen Daten und Milestones (semantisch) enthält. Dieses Modell wird im W3C Standard RDF 1.2 in der Funktion als (temporaler) Context Graph verwendet und garantiert dadurch eine vollständige, semantische Betrachtung aller Vorgänge zu jedem Zeitpunkt – auch in der Retrospektive – sowie die Interoperabilität mit anderen internen oder externen Prozessen.
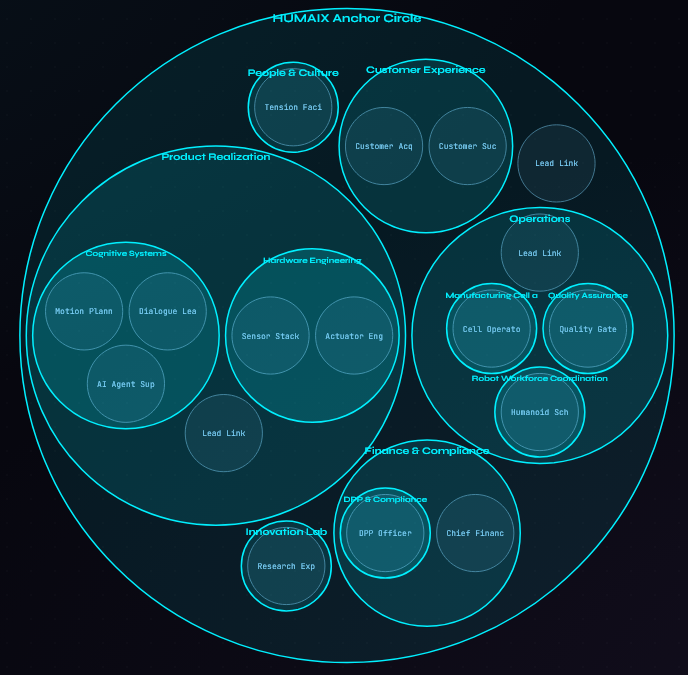
Übersicht der Circles & Roles des Unternehmens
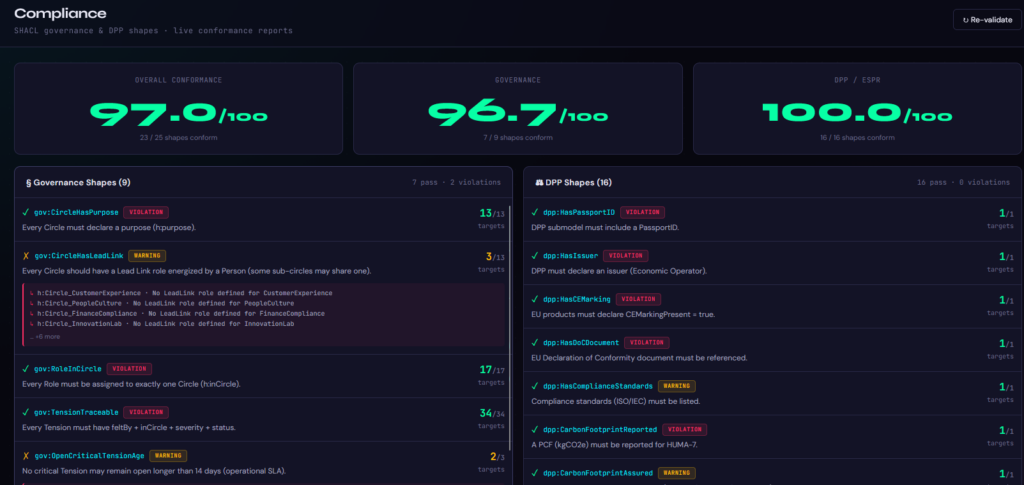
Governance und DPP Compliance Dashboard des Prototypes